Introduction
This blog post started with the goal of writing a powershell script that would allow you to find non EN-US characters living on your system, along with obfuscated command characters. This is the reverse of my last blog post.
There's some weird quirks with powershell and unicode, which I'll document below.
Before I go any further, the code is built on the work by @sysadm2010
His article is a wealth of knowledge for powershell and unicode, I can't suggest reading it it enough.
TLDR: Powershell is weird, but can help!
All of the scripts for article was written and tested on Windows 10 Pro Build 1607.
The following character code points cause unexpected behavior
- U0130 This code point appears in every Windows filename/username/service as tested
- UFFFC This code point is converted to a basic space
However, it can help find some obfuscation
Setup
I used the following character strings for testing:
Finding Unicode Files
As mentioned I'm relying on @sysadm2010's work. As such the code snippits you see are from him, I'm just using it to show how you can find obfuscated files/users/services.
Also this blog post assumes you recall from my last blog post "Pop" U202C can be used to make impossible to visually distinguish files/users/services/etc
First, lets look for all files.
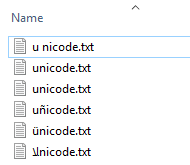
get-childitem C:\vgrsec -recurse |
Where {$_.Name -Match "[\u0000-\uFFFF]"} |
select @{label="File Name";Expression={$_.BaseName};},
Directory, @{label="Date Created(UTC)";Expression={$_.CreationTimeutc}},
@{label="Date Modified(UTC)";Expression={$_.LastWriteTimeutc}},
@{Label="File Size(KB)";Expression={$_.length / 1kb -as [int32]}} | Format-Table
Seems sane. So lets tighten it up, and find all files outside of EN-US. According to Microsoft EN-US (Basic Latin) starts at 0000 ends at 007F.
So, with this info, lets look for all characters higher than 007F.
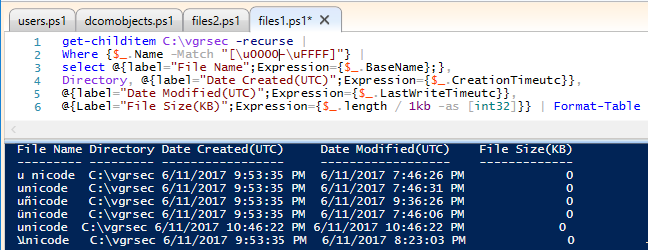
Where {$_.Name -Match "[\u007F-\uFFFF]"} |
WTF Why is unicode there (highlighted, the other unicode is "Pop" Unicode)
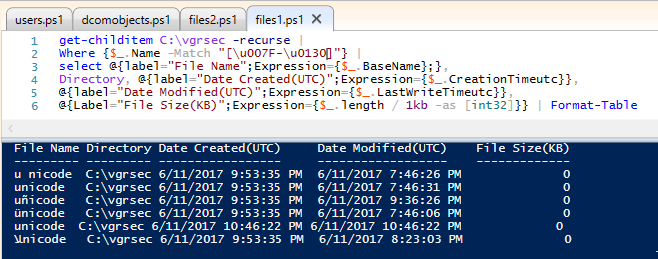
After some digging this is where U0130 gets its time to shine. As you can see below, we get results as expected
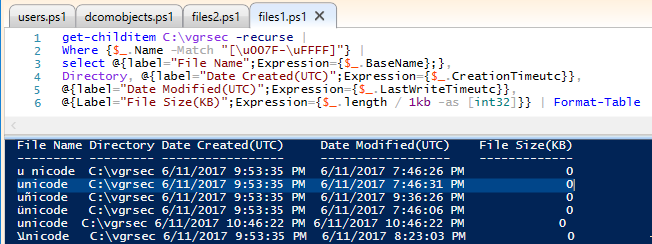
Where {$_.Name -Match "[\u007F-\u012F]"} |
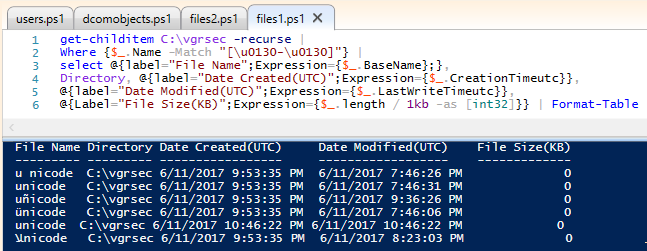
Hold my beer, this is where things get weird.
Where {$_.Name -Match "[\u007F-\u0130]"} |
Where {$_.Name -Match "[\u0130-\u0130]"} |
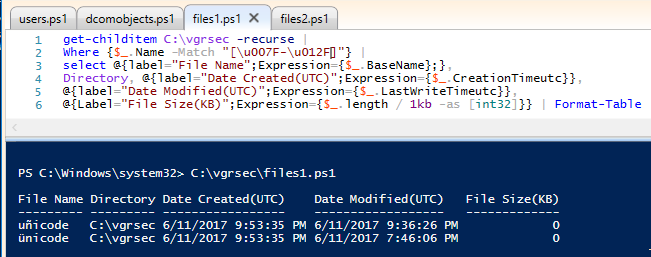
Where {$_.Name -Match "[\u0131-\uFFFF]"} |
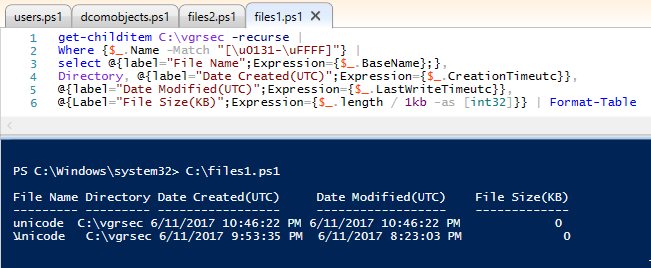
Ok this makes sense
UFEFC
+nicode is higher than u0131, the rest are lower
Also, now "Pop" has nowhere to hide. That is the lookalike unicode
Where {$_.Name -Match "[\u0020-\u0020]"} |
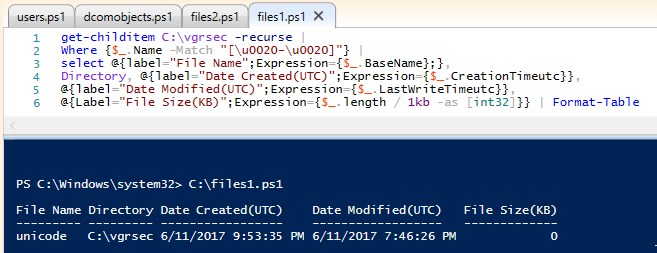
Ok, so here's a thing to learn, copying U+FFFC into clipboard and pasting it into explorer converts it to a space.
However, I have no idea why u0130 ends up existing in every file in the Windows file system. If you know why, I'd love to learn
Finding Unicode Users
Rather than bore everyone with a ton of screenshots pretty much the same principals as before are true for finding files.
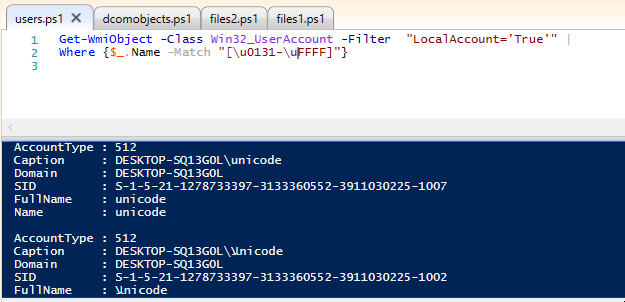
U0130 is in every user name, and I can't explain why. So, here's a single screenshot showing "Pop" as a user
Get-WmiObject -Class Win32_UserAccount -Filter "LocalAccount='True'" |
Where {$_.Name -Match "[\u0131-\uFFFF]"}
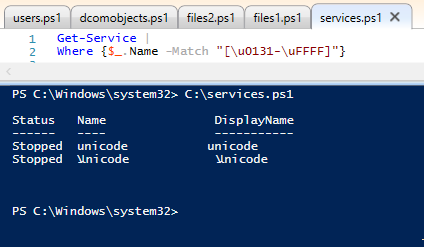
Finding Unicode Services
Service hunting!
U0130
is ALSO in every service name. shakes head
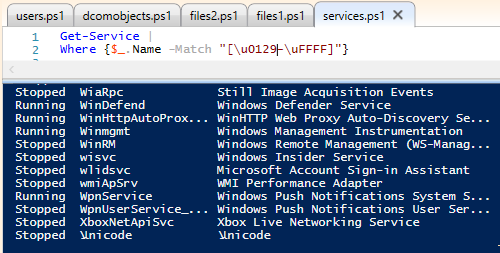
So, here's a single screenshot showing "Pop" as a service
Get-Service |
Where {$_.Name -Match "[\u0131-\uFFFF]"}
Conclusions
I'm not a powershell ninja by any stretch of the imagination, but this should provide some insight into using powershell to crawl your systems for out of place characters. I have no doubt that COM/DCOM objects would work similar, but I don't have working code to demonstrate that.
Furthermore, if I get some time, I'll whip up a script that captures everything not in EN-US, while excluding U0130... or maybe someone better at powershell than I am will do it, at which point, I'll update this post linking to their work
Idealy, a powershell script would detect the local language, then scan for all 'out of local script' characters. Not entirely sure how I'd do that.