Introduction
In my last piece, I discussed how Unicode Domains are bad. This blog focuses completely on a Windows environment, and how Windows handles specific special Unicode characters.
The quick take away is that an attacker can craft file names, service names, com objects, and usernames in such a way that in many parts of the system and logs, they are indistinguishable from one another. This is bad because it can increase the complexity to detect malicious behavior on a system.
Shout out to @Laughing_Mantis who taught me about a technique of using the "No Break Space" (U+00A0) as a user name several years ago. This work expands upon this concept.
Lastly, I'm certain this isn't new, this is really just an all-in-one collection of how Windows handles Unicode in different parts of the system.
All tests were performed on Pro build 10.0.14393.953 however, I have no reason to believe this functionality has changed since Windows 7, or is different on server editions.
TLDR: Conclusion
Using Unicode, one can create near duplicate files, usernames, services, com objects, and likely other Windows objects that are difficult to differentiate. This is possible because for many control characters Windows shows nothing in the GUI. In command line tools, it will show a filler character, but often Windows Administrators rely on their GUI tools for ease of use and lack of familiarity with Command tools.
Demonstration
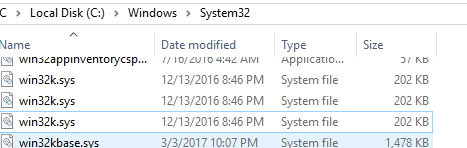
Three identical files? Bet you can't tell which is real.
This isn't a trick! All 3 files coexist with one another.
This blog has three characters. Real, Pop, and Zero.
- Real - Real is "the real thing" no tricks no Unicode.
- Pop - Pop is the "Pop Directional Formatting" (U+202C)
- Zero - Zero is the "Zero Width Space" (U+202C)
Zero often acts like a space when sorting lists. Append it to a word and that word will come first in alphabetical order.
Pop on the other hand always seems to cause whatever it appends to come last in alphabetical order
Since both react differently we can do some comparison, as such from here on out, rather than refer to the control code, I will refer to them by Real, Pop, and Zero. It'll be easier to follow along.
As an aside, there are a lot of other control characters, they mostly seem to react like Pop or Zero. However, a unique one is U+FFFC "Object Replacement Character". I'll talk about that at the end.
Setup
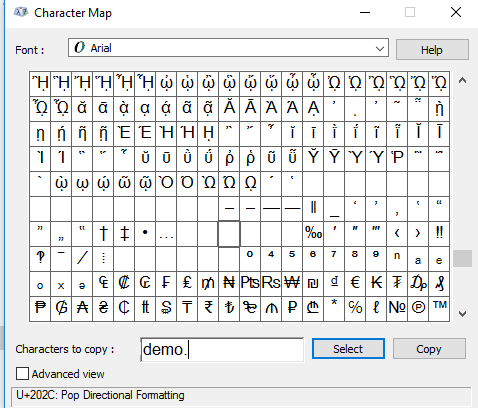
If you wish to follow along, open up notepad and charmap.exe. The control characters I'm using are near the bottom. In the text field in charmap craft demo(control character). and paste it into separate lines in notepad. This will give you something to copy and paste into text fields.

Findings
Files
I created 3 file names, and to Windows Explorer they all looked the same
- demo.txt
- demo(Zero).txt
- demo(Pop).txt
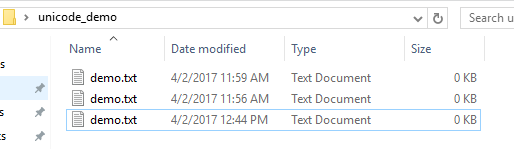
Zero is top, Real is in the middle, Pop is on the bottom.
Command Prompt & Powershell react differently
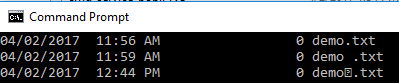

Command Prompt displays one of the Unicode characters (Zero)
Powershell just shows a Unicode filler character
Services
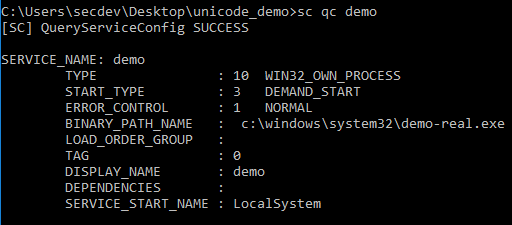
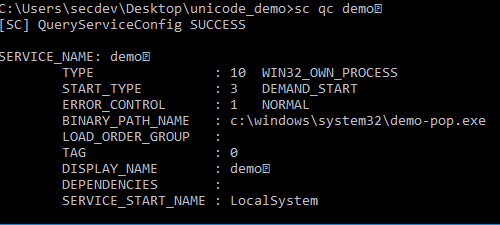
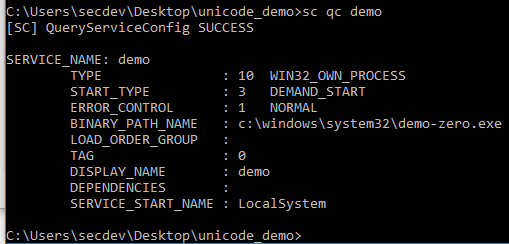
I created three services using the command below. I used the path to keep the 3 services straight.
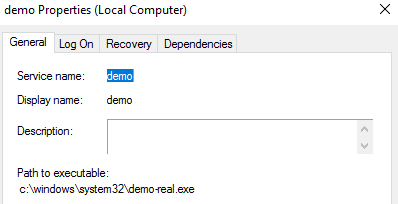
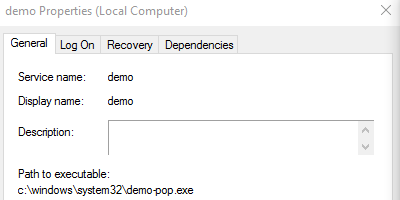
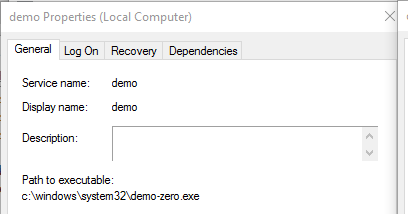
sc create demo binpath= c:\windows\system32\demo-real.exe displayname ="Demo"
sc create demo(Zero) binpath= c:\windows\system32\demo-zero.exe displayname= "Demo(Zero)"
sc create demo(Pop) binpath= c:\windows\system32\demo-pop.exe displayname= "Demo(Pop)"
This gave me three identical looking services
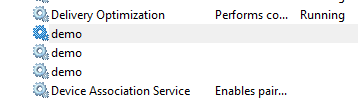
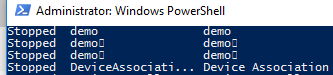
Note, there was some odd behavior in the services snap-in that I can't reproduce consistently. Sometimes the Pop service show up twice and real would vanish. Other times the order would change. Sometimes refreshing would change the order/behavior. I tried to figure out the pattern but was unsuccessful.
However, once again, command line can show us the way.
If you have a service, that means you have events! I tried to start my fake services, which obviously failed since I didn't create a binary to go with it, but it gives us a clue as to how they'll show up in the event logs. Links go to the evtx files.
| Real |
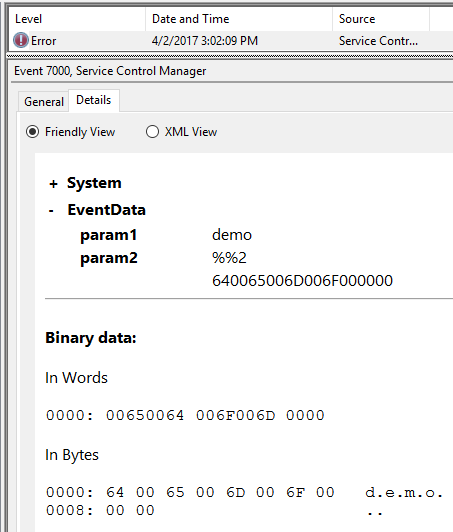 |
| Pop |
 |
| Zero | 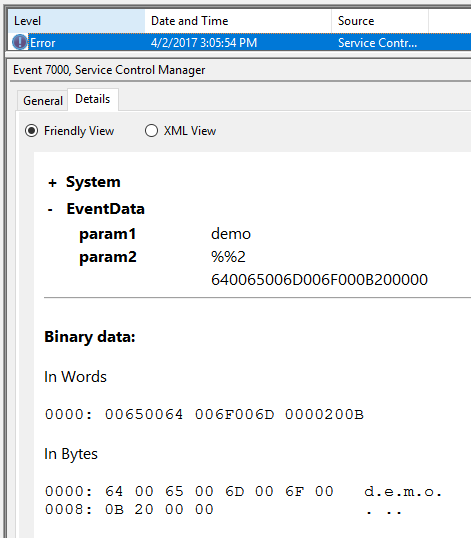 |
Users
I then created some users using the GUI. This too had some strange behavior. Sorted A-Z the list goes Real, Pop, Zero. Sorted Z-A it goes Zero, Real, Pop. If it were consistent one should remain in the middle. Something about MMC and Unicode is just weird. (I never found the root cause)
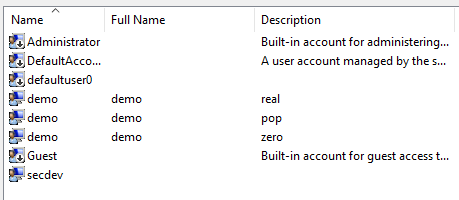
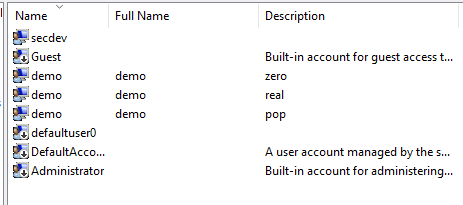
These users logged in as any other normal user, and the system created their home directories using the correct Unicode characters.

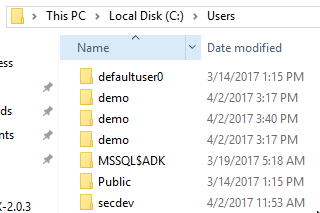
Once again, with users, comes logs. However, it quickly became apparent that I needed to know the SIDs to keep the users straight
wmic useraccount get name,sid,description
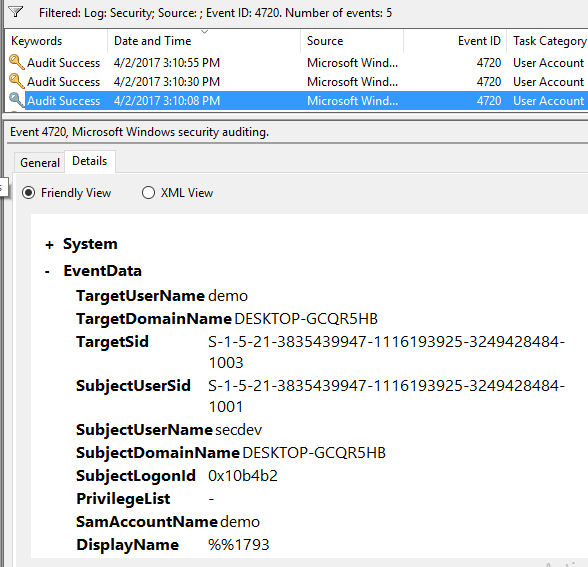
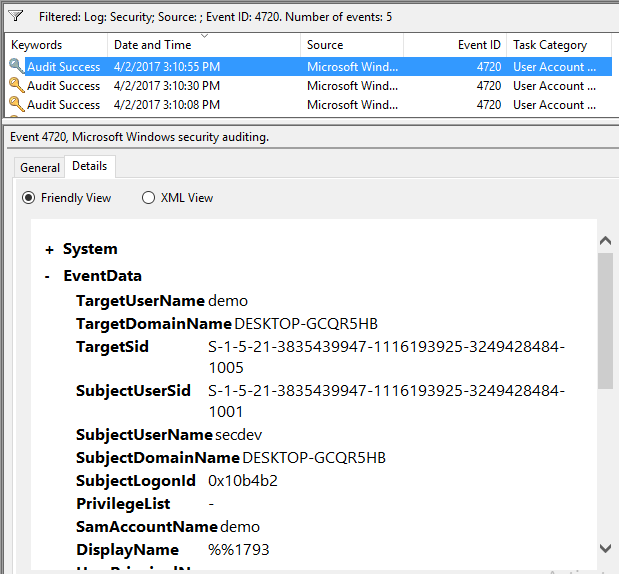
Real - 1003 | Zero - 1004 | Pop - 1005
I'm only showing EventID 4720, but its enough to show how the SamAccountName looks identical in the logs across all 3 accounts.
| Real |
 |
| Pop |
 |
| Zero | 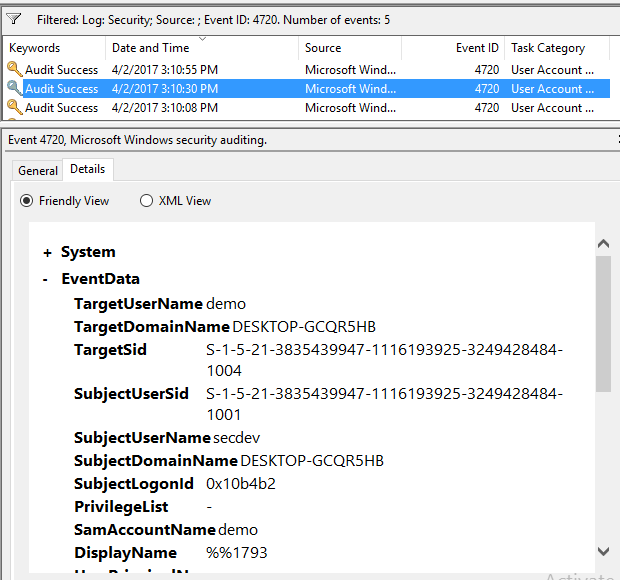 |
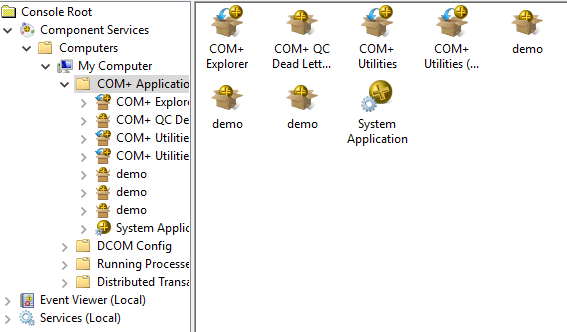
COM Objects
Last but not least, I created some COM Objects. Once again, they look the same.
U+FFFC Object Replacement Character
I don't have any good screenshots around this, so this is more of a narrative about what I observed with the Object Replacement Character (ORF). In my file system tests I created (ORF)demo.txt. This caused a file duplication prompt. Same with d(ORF)emo.txt However, if I did demo(ORE).txt or demo.(ORE)txt it would work. Something about the ORE at the end of the file name or in the file type caused it to get read by the file system. I didn't play with it too much more.
Wrap Up
If you've made it this far, you probably already have some ideas with what an attacker can do with this. Name obfuscation using this technique could cause confusion at many different levels. If you're running monitoring tools, it would likely make sense to test if your logging tools highlight Unicode in filenames/usernames/etc If you're writing software, these control characters should show up as a Unicode placeholder unless there's a strong case for it to not be displayed. As far as I know there's no mitigation to this in the Windows GUI, so if you come across this in an investigation, run powershell, it's the most reliable in displaying Unicode placeholders.